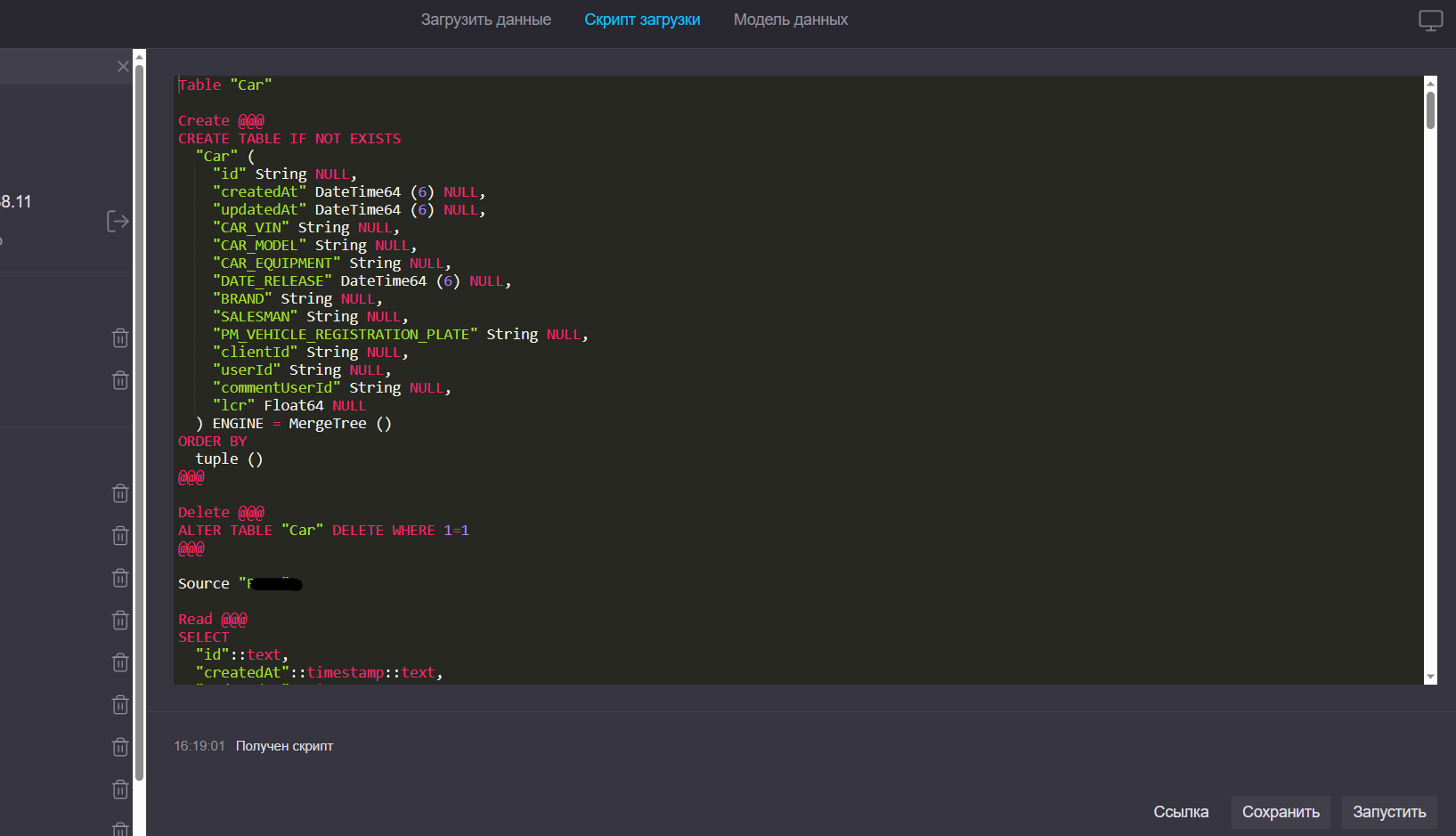
Редактор скрипта загрузки
Скрипт загрузки генерируется автоматически после выбора источников данных.
Этап ручного редактирования скрипта загрузки является необязательным, однако функциональность Fastboard позволяет при необходимости внести изменения.
Правила использования редактора
Добавить источник
| Шаги | Ожидаемый результат |
|
В любом месте скрипта добавить строку где:
|
|
Добавить таблицу из источника
| Шаги | Ожидаемый результат |
|
|
Удалить таблицу
| Шаги | Ожидаемый результат |
|
Удаленная таблица исчезла из списка таблиц на странице модели данных |
Добавить поле из таблицы источника в таблицу импорта
| Шаги | Ожидаемый результат |
|
На странице модели данных в данной таблице появилось поле "id" с типом данных, указанным в секции Create |
Удалить поле из таблицы
| Шаги | Ожидаемый результат |
|
Удаленное поле исчезло таблицы на странице модели данных |
Изменить тип данных поля
| Шаги | Ожидаемый результат |
|
Тип поля изменился в таблице |
В настоящий момент для применения любых изменений в таблицах (создание поля, переимнование поля, изменение типа поля и т.д.) необходимо пересоздать таблицу в БД проекта. Для этого после внесения всех изменеий к имени таблицы можно добавить, например _1, после этого сохранить, затем запустить скрипт. При необходимости вернуть таблице старое название тем же способом. (Это связано с текущими ограничениями парсера. Мы над этим работаем)
Создать вычисляемое поле в таблице
| Шаги | Ожидаемый результат |
|
При импорте таблицы из источника перед вставкой таблицы в КХ можно создать поле которого нет в исходной таблице, но которое будет вычислено и создано на основе заданного выражения. Для этого:
|
В таблице появится поле с назначенным типом данных и рассчитанными по заданному выражению значениями |
Создать новую таблицу "Календарь"
Вставить в скрипт загрузки следующий текст (обратите внимание на комментарии), после выполнения скрипта загрузки выполнить JOIN таблицы Calendar к вашей таблице фактов.
Table "calendar"
Create @@@
CREATE TABLE IF NOT EXISTS
"calendar" (
"id" Int32 NULL,
"key_date" String NULL,
"date" Date32 NULL,
"index_day" Int32 NULL,
"day" String NULL,
"week" Int32 NULL,
"quarter" Int32 NULL,
"year" Int32 NULL,
"index_month" Int32 NULL,
"month" String NULL
) ENGINE = MergeTree ()
ORDER BY
tuple ()
@@@
Delete @@@
ALTER TABLE "calendar" DELETE WHERE 1=1
@@@
Source "promo_fb (RomanS)" -- Укажите любой существующий источник, чтобы сохранить в него вашу таблицу
Read @@@
SELECT
a."id"::text,
a."key_date"::text,
a."date"::text,
a."index_day"::text,
a."day"::text,
a."week"::text,
a."quarter"::text,
a."year"::text,
a."index_month"::text,
a."month"::text
FROM
(
select distinct
row_number() over() as id,
date(date)::text as key_date,
date::date,
extract('isodow' from date) as index_day,
CASE
WHEN extract('isodow' from date) = 1 then 'ПН' -- Если нужно, укажите названия дней (и месяцев ниже)
WHEN extract('isodow' from date) = 2 then 'ВТ'
WHEN extract('isodow' from date) = 3 then 'СР'
WHEN extract('isodow' from date) = 4 then 'ЧТ'
WHEN extract('isodow' from date) = 5 then 'ПТ'
WHEN extract('isodow' from date) = 6 then 'СБ'
WHEN extract('isodow' from date) = 7 then 'ВС' end as day,
extract('week' from date) as week,
extract('quarter' from date ) as quarter,
extract('year' from date) as year,
extract('month' from date) as index_month,
CASE
WHEN extract('month' from date) = 1 then 'Январь'
WHEN extract('month' from date) = 2 then 'Февраль'
WHEN extract('month' from date) = 3 then 'Март'
WHEN extract('month' from date) = 4 then 'Апрель'
WHEN extract('month' from date) = 5 then 'Май'
WHEN extract('month' from date) = 6 then 'Июнь'
WHEN extract('month' from date) = 7 then 'Июль'
WHEN extract('month' from date) = 8 then 'Август'
WHEN extract('month' from date) = 9 then 'Сентябрь'
WHEN extract('month' from date) = 10 then 'Октябрь'
WHEN extract('month' from date) = 11 then 'Ноябрь'
WHEN extract('month' from date) = 12 then 'Декабрь'end as month
from generate_series(date'2015-01-01',date(now()),interval '1 day')as t(date) -- Выберите дату начала и интервал
order by
date desc) a
@@@
Таблица в результате:

Некоторые особенности работы разными типами источников
MS SQL
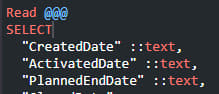
1. При импорте данных с типом «Дата» нужно будет поля с датами в секции READ для этой таблицы сконвертировать в строку. КХ сам сконвертирует тип дата при создании таблицы у себя и они снова станут датами
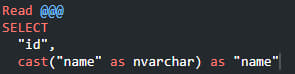
2. Поля с кодировкой UTF16 (тип varchar) нужно будет обернуть в cast. В той же секции @READ для этой таблицы. Иначе русскоязычные значения не распознаются в этих полях и появятся вопросительные знаки