Диспетчер данных
- Источники данных
- Источник – Google Таблицы
- Выбор данных для загрузки
- Редактор скрипта загрузки
- Модель данных
Источники данных
Для получения данных необходимо перейти на страницу диспетчера данных. Для этого кнопка с изображением базы данных находится в правом верхнем углу страницы визуального редактора дашборда:
Чтобы вернуться в визуальный редактор дашборда в том же правом верхнем углу кнопка с изображением монитора
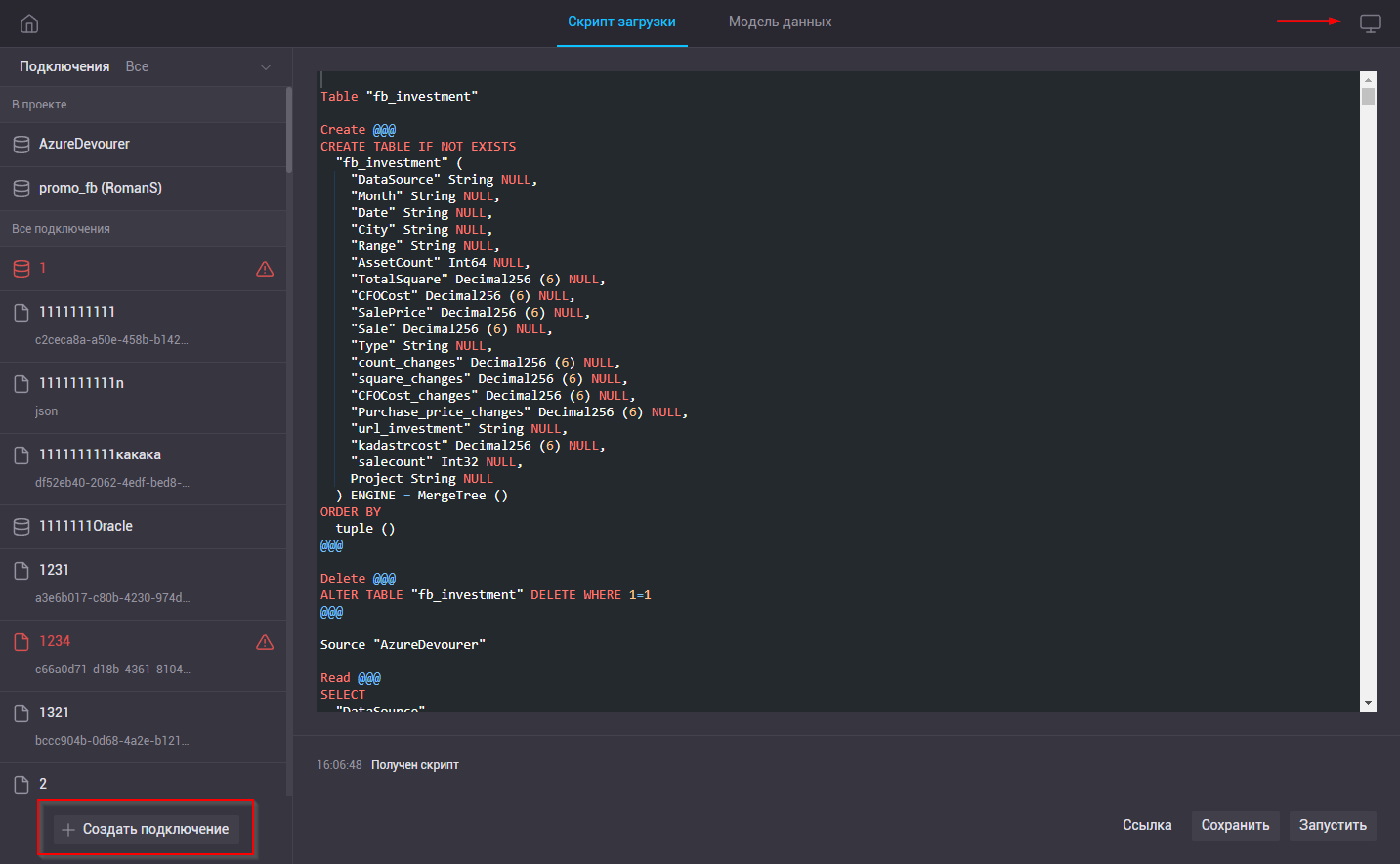
Диспечер данных дашборда представляет собой две страницы. «Скрипт загрузки» со списком источников и «Модель данных». Источники создаются на первой из них.
В левой части страницы скрипта находится список созданных подключений. Этот список состоит из двух секций:
- В проекте. Сюда попадают конекторы данные из которых уже используются в проекте
- Все подключения. Весь список подключений доступных пользователю.
Если при создании подключения были недозаполнены реквизиты подключения и/или проверка соединения не прошла успешно, этот коннектор всеравно можно сохранить, но он будет помечен красным цветом. После этого в списке подключений появится новый источник с указанным названием.
Создание подключения
Итак, для создания нового коннектора на странице «Скрипта загрузки» в сайдбаре слева нажимаем кнопку «Создать подключение» внизу списка коннекторов.
![]()
После чего появится диалоговое окно в котором нужно выбрать один из доступных типов источника.
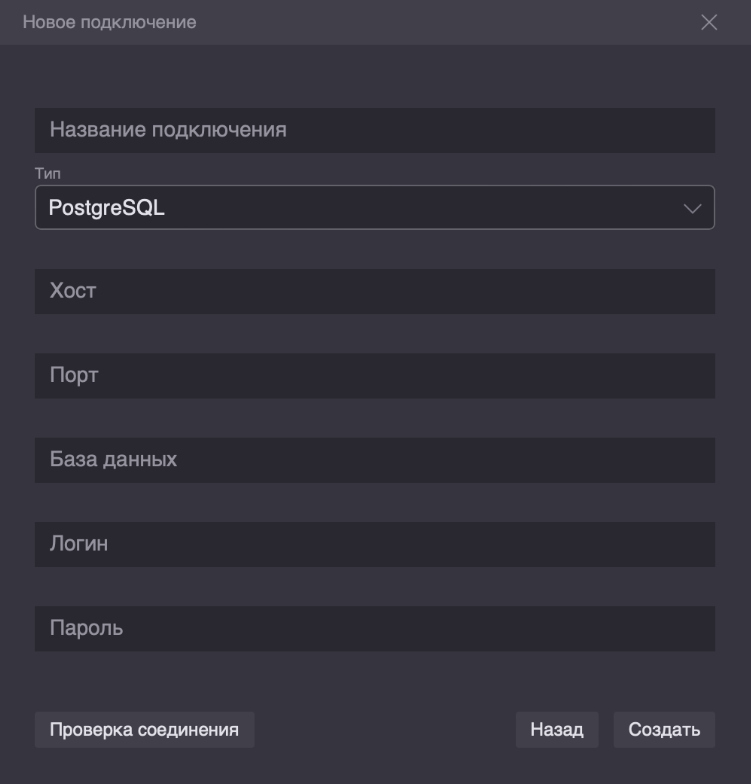
База данных
Где необходимо заполнить реквизиты подключения:
- Название подключения
- СУБД
- Click House
- PostgreSQL
- MS SQL
- Oracle
- MY SQL (еще в разработке)
- Хост
- Порт
- База данных
- Логин
- Пароль
Для Click House будет доступен дополнительный параметр HTTP/HTTPS
Для Oracle нужно будет указать формат даты, т.к. у каждого экземпляра этой СУБД формат даты может отличаться
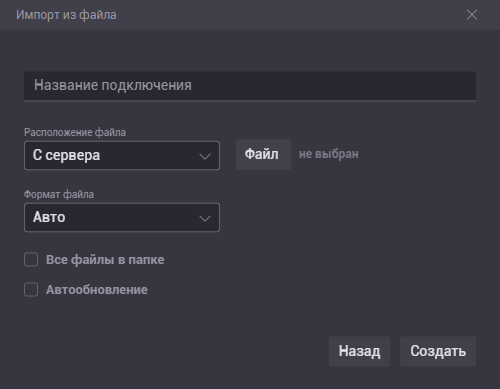
Файл
- В модальном окне заполнить/выбрать:
- Название подключения
- Расположения файла:
- Загрузить. Файл также может быть загружен с локального компьтера пользователя. Но есть ограничение по объему 25мб. Размер может быть изменен в настройках системы. Папка для загрузки по умолчанию :
/opt/fastboard/upload_{имя окружения} - С сервера. Папка Upload на вашем сервере, куда можно положить файл любого размера сторонними средствами
- Загрузить. Файл также может быть загружен с локального компьтера пользователя. Но есть ограничение по объему 25мб. Размер может быть изменен в настройках системы. Папка для загрузки по умолчанию :
- Формат файла определится автоматически, если форматы CSV, TXT, JSON, XLS/XLSX, XML, QVD. Другие форматы не поддерживаются, но загрузить их можно, если в них структура данных одного из поддерживаемых форматов, то необходимо выбрать этот формат вручную
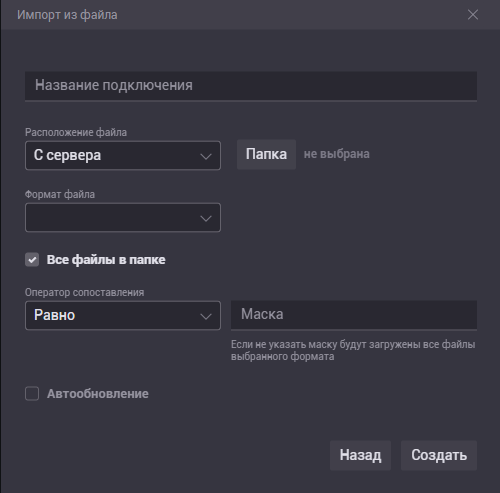
- Все файлы в папке. Если отметить это чекбокс в выборе расположения будет только сервер, формат файла необходимо можно выбрать только вручную, будут выбраны все файлы выбранного формата содержащиеся в папке, а ткже появится поле для ввода маски для имени файла. Если указать маску, то выберутся только файлы подходящие под заданные условия
- Автообновление. Система будет отслеживать изменения файла, или файлов. Если это произошло БД созданная из этого файла или файлов будет автоматически обновлена согласно произошедшим изменениям.
Один файл Несколько файлов 

- После выбора параметров необходимо нажать кнопку "Создать" для того, чтобы начать загрузку данных из файла в хранилище данных Fastboard.
- Из файла или файлов будет создан коннектор. В списке подключений появится новый источник с указанным названием из которого можно будет выбирать данные для проектов.
После успешного создания подключения можно переходить к выбору и загрузке данных
Удаление коннектора
Может быть двух типов:
1. Из проекта.
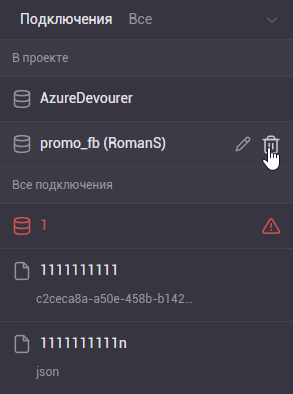
Нажатием на кнопку корзинки в списке коннектов проекта можно удалить все данные этого источника из скрипта загрузки. После чего нужно запустить скрипт чтобы обновить данные проекта/
Внимание. Перед удалением коннекта из проекта убедитесь, что таблицы удаляемого источника не входят ни в одну из моделей данных проекта. Иначе эти модели и сам проект сломаются. Если такое все же произошло, то чтобы восстановить работоспособность проекта нужно загрузить все те же данные обратно в проект.
2. Из списка коннектов. Если у пользователя есть права на управление источником, он может удалить его из системы. Для этого нужно вызвать модальное окно редактирования коннектора и в нем нажать кнопку «Удалить подключение»
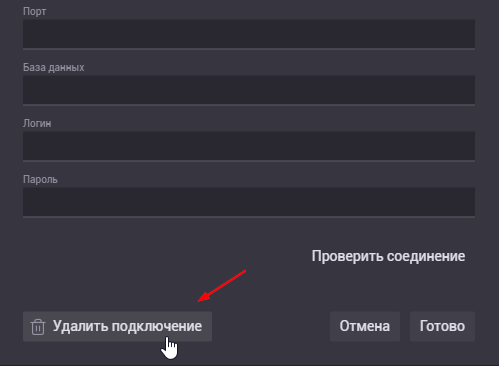
Доступ к коннекторам
Для того чтобы коннектор созданный пользователем или администратором был доступен другим пользователям, необходимо предоставить им доступ. Существуют два вида прав доступа к коннекторам:
- Управление. Пользователь видит коннектор в общем списке, может использовать в своих проектах. А также может изменить данные этого подключения, удалить подключение. Предоставить доступ другому пользвателю.
- Использование. Пользователь видит коннектор в общем списке и может только использовать коннект в своих проектах.
Для распределения прав пользователям у каждого конектора есть две таблицы Управление и Использование. Когда пользователь создает коннектор он автоматически получает права на управление. И получает все привилегии и распоряжается правами на это подключение.
Пользователь с ролью «Администратор» всегда имеет права на управление любым коннектором. Всегда видит все конекторы и может ими распоряжаться.
В данный момент это функционал доступен только через API
Источник – Google Таблицы
Подготовка источника с помощью скрипта
- Активировать API для Google таблиц. Для этого:
- Открыть Google Cloud Console
- Войти под той учётной записью, под которой была создана Google таблица
- В навигационном меню ("бургер") выбрать "APIs & Services" → "Library"
- Найти в списке Google Sheets API, зайти внутрь, включить настройку (нажать на "Enable")
- Перейти в Google таблицу, к которой необходимо подключиться как к источнику. Выбрать "Настройки доступа" – "Общий доступ" – "Все, у кого есть ссылка" – "Редактор"
- В строке меню таблицы сверху выбрать "Расширения" – "Apps Script" и настроить расширение следующим образом:
- Записать следующий скрипт:
function doGet() { var sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet(); var data = sheet.getDataRange().getValues(); var csvData = data.map(row => row.join(",")).join("\n"); return ContentService.createTextOutput(csvData).setMimeType(ContentService.MimeType.CSV); } - Сохранить проект (например, с помощью сочетания клавиш Ctrl + S)
- Попытаться "Выполнить" нажатием на соответствующую кнопку на верхней панели. При этом может потребоваться повторно войти в Вашу учётную запись – необходимо сделать это. В случае ошибки подключения необходимо закрыть окно входа и попытаться выполнить скрипт повторно
- После успешного выполнения скрипта нажать на кнопку "Начать развёртывание" → "Новое развёртывание". в развёртывании выбрать тип (нажатием на "шестеренку" слева сверху) – "Веб-приложение". В настройках конфигурации указать:
- "Запуск от имени" – "От моего имени"
- "У кого есть доступ" – "Все"
- Нажать на кнопку "Начать развёртывание"
- После создания развёртывания в секции "Веб-приложение" будет доступен URL – именно он понадобится в создании подключения. Повторно получить этот URL можно всё в том же скрипте "Apps Script" для подключаемой таблицы с помощью "Начать развёртывание" → "Управление развёртываниями"
- Записать следующий скрипт:
ДОПОЛНИТЕЛЬНО. К Google таблице можно подключиться и без использования Apps Script. В таком случае выходной массив данных формируется построчно, причём каждая строка выступает отдельным массивом и отобразится в источнике в Fastboard как отдельная таблица. При подключении без скрипта понадобятся ID таблицы-источника и API-ключ:
- ID таблицы можно извлечь из адресной строки самой таблицы – он расположен между d/ и /edit
- API-ключ можно получить в Google Cloud Console. Для этого необходимо:
- В навигационном меню выбрать APIs & Services → Credentials
- Нажать на кнопку "Create credentials", выбрать "API key"
- После создания ключа нажать на него в таблице ниже, откроется окно для редактирования. В этом окне необходимо в секции "API restrictions" выбрать "Restrict key", найти и выбрать в раскрывающемся списке Google Sheets API
- Вернуться на шаг назад, нажать на кнопку "Show key" для вашего ключа, скопировать ключ
Подключение к источнику через API (Postman, Swagger)
После подготовки источника необходимо настроить подключение через API. Выполнить подключение можно как через Postman, так и через Swagger. Потребуется выполнить 2 запроса – для авторизации на Fastboard и настройки подключения к Google таблице:
- POST-запрос на авторизацию – https://СТЕНД_FASTBOARD/api/auth/get_token:
- При подключении через Postman в теле запроса (body) необходимо выбрать тип "row" и из раскрывающего списка "json". Написать скрипт:
{ "login": "Ваш логин на стенде", "password": "Ваш пароль на стенде" }Запустить скрипт с помощью кнопки "Send"
- При подключении через Postman в теле запроса (body) необходимо выбрать тип "row" и из раскрывающего списка "json". Написать скрипт:
- POST-запрос на подключение – https://СТЕНД_FASTBOARD/api/v2/source:
-
- При подключении через Postman в теле запроса (body) необходимо выбрать тип "row" и из раскрывающего списка "json". Написать скрипт:
{ "name": "Название подключения, которое будет отображаться в модели данных", "driver": "rest-api", "credentials": { "url": "Ссылка из развёртывания из шага 3", "method": { "value": "GET" }, "format": { "value": "csv", //формат файла, в скрипте установили csv "noHeaders": false //использовать первую строку как заголовок (false, чтобы использовать) } }, "isAutoUpdate": false //требуется ли автообновление (false, если не требуется) }Запустить скрипт с помощью кнопки "Send"
- При подключении через Postman в теле запроса (body) необходимо выбрать тип "row" и из раскрывающего списка "json". Написать скрипт:
После успешного отправления POST-запросов в поле ответа "Response" должен отобразиться код ответа "201" – источник успешно создан.
Найти источник можно в диспетчере данных любого проекта на указанном в запросах стенде (название соответствует "name" из скрипта). В источнике будут содержаться две таблицы – "main" (системная) и "data" (данные с листа). Помимо самих данных в таблице "data" будут присутствовать два системных столбца, содержащие ID каждой строки и ID из таблицы "main".
ДОПОЛНИТЕЛЬНО. При подключении к таблице без Apps Script в POST-запросе на подключение необходимо указать следующий скрипт:
{
"name": "Название подключения, которое будет отображаться в модели данных",
"driver": "rest-api",
"credentials": {
"url": "https://sheets.googleapis.com/v4/spreadsheets/ID_ТАБЛИЦЫ_ИСТОЧНИКА/values/Sheet1!A1:C11?key=API_КЛЮЧ_ИЗ_КОНСОЛИ",
"method": {
"value": "GET"
},
"format": {
"value": "json" //передаваемый формат – json
}
},
"isAutoUpdate": false //требуется ли автообновление (false, если не требуется)
}В источнике на стенде будет указано столько таблиц, сколько было строк в Google таблице, + системные таблицы.
Выбор данных для загрузки
Для просмотра и выбора данных доступных в конкретном источнике необходимо кликнуть на нем в этом списке.
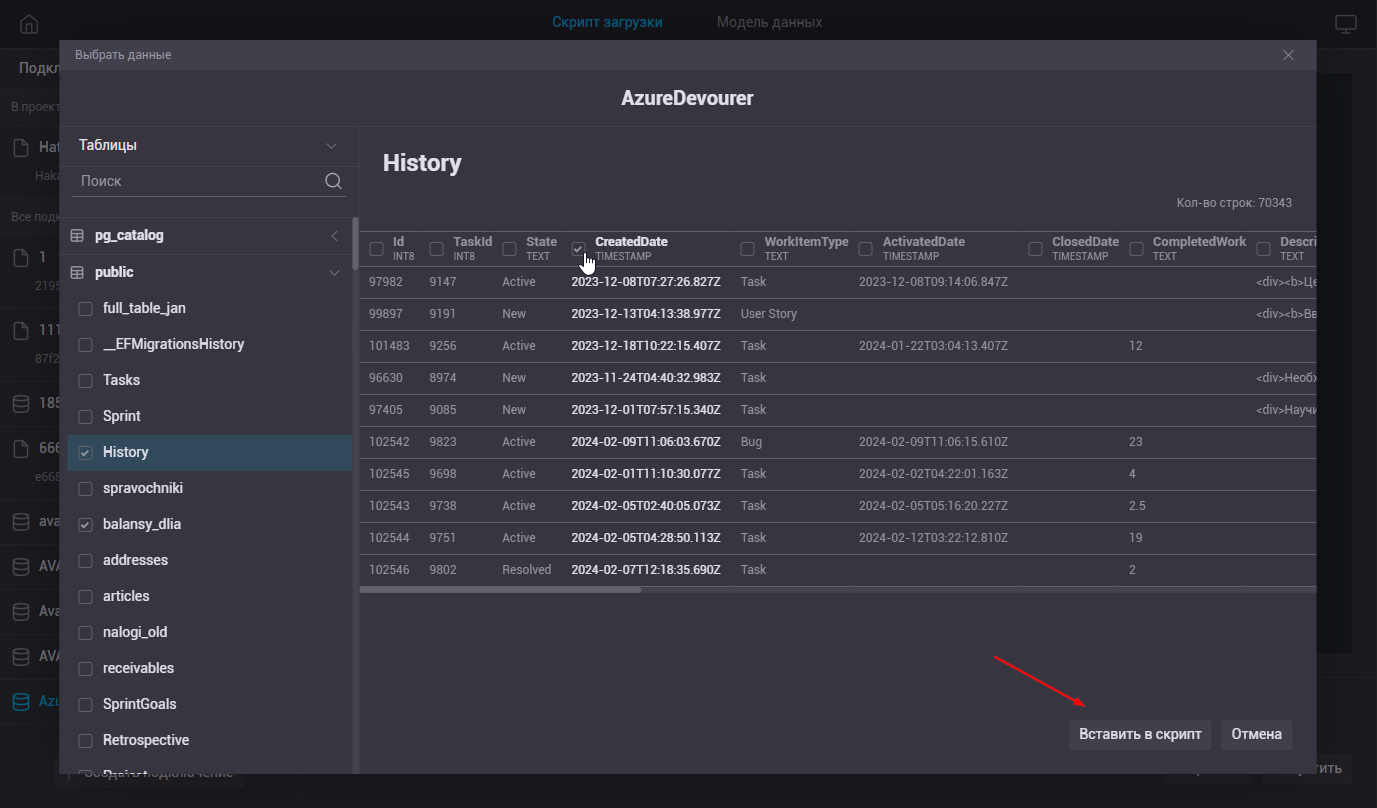
После того как выбор сделан нажимаем кнопку «Вставить в скрипт». После этого окно закроется и мы увидим скрипт загузки сгенерировный для импорта выбраннцих таблиц и полей.
Для того чтобы запустить импорт данных нужно сначала «сохранить» скрипт, и далее «Запустить».
После успешной загрузки данных на экране появится соответствующее сообщение.
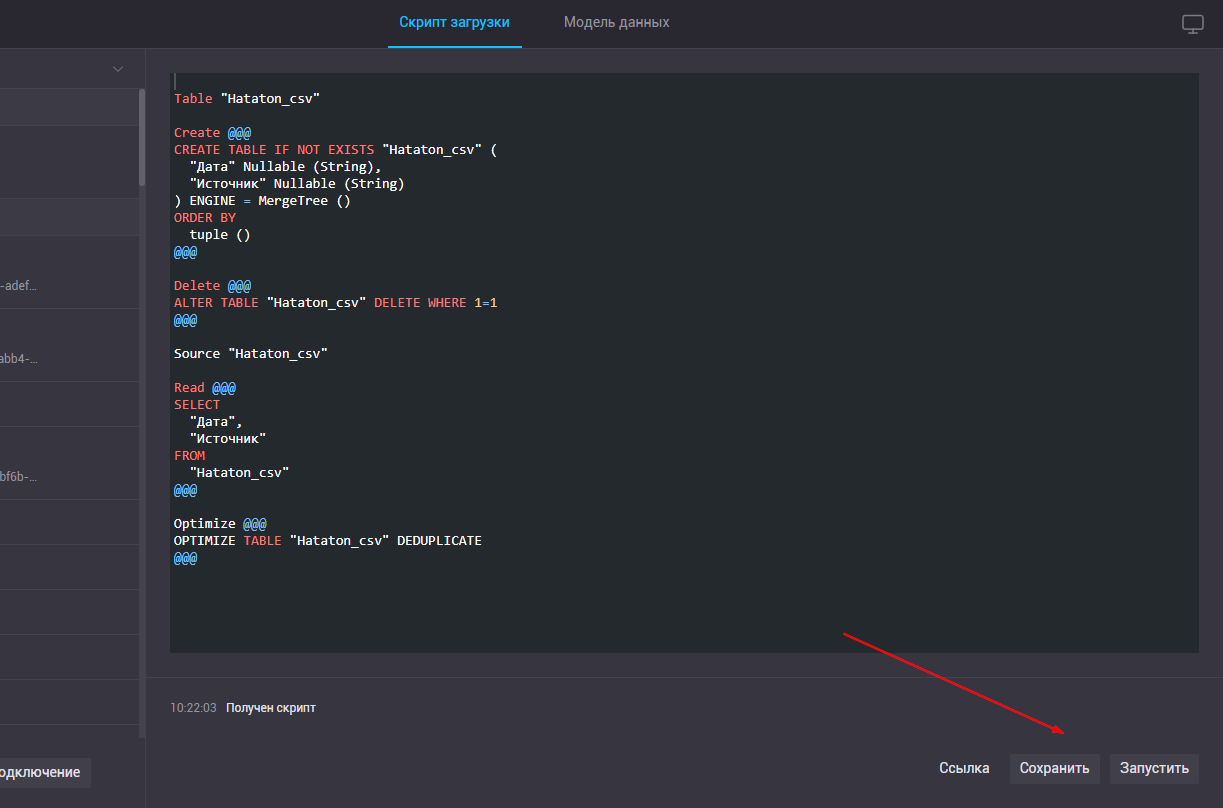
Редактор скрипта загрузки
Скрипт загрузки генерируется автоматически после выбора источников данных.
Этап ручного редактирования скрипта загрузки является необязательным, однако функциональность Fastboard позволяет при необходимости внести изменения.
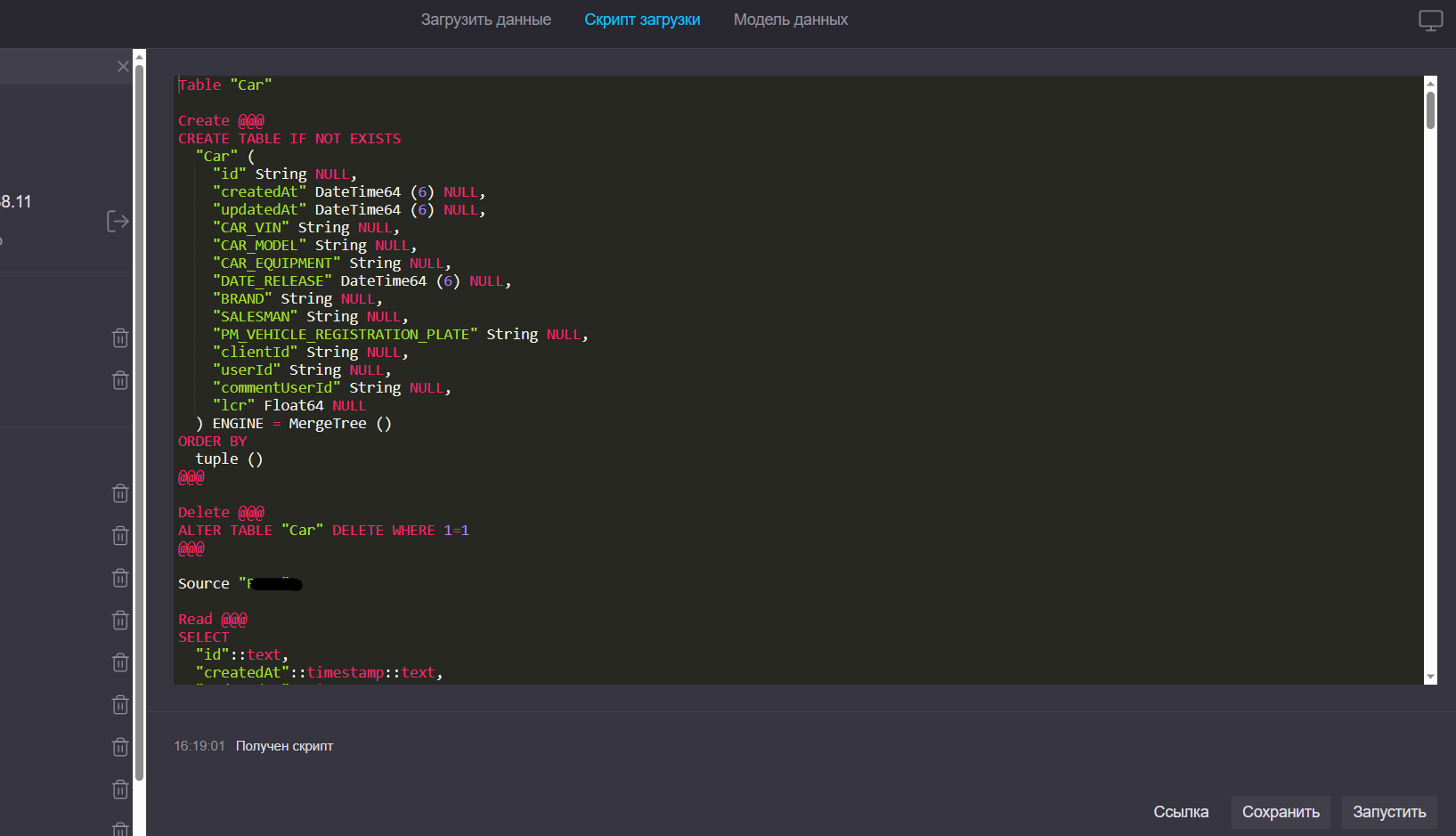
Правила использования редактора
Добавить источник
| Шаги | Ожидаемый результат |
|
В любом месте скрипта добавить строку где:
|
|
Добавить таблицу из источника
| Шаги | Ожидаемый результат |
|
|
Удалить таблицу
| Шаги | Ожидаемый результат |
|
Удаленная таблица исчезла из списка таблиц на странице модели данных |
Добавить поле из таблицы источника в таблицу импорта
| Шаги | Ожидаемый результат |
|
На странице модели данных в данной таблице появилось поле "id" с типом данных, указанным в секции Create |
Удалить поле из таблицы
| Шаги | Ожидаемый результат |
|
Удаленное поле исчезло таблицы на странице модели данных |
Изменить тип данных поля
| Шаги | Ожидаемый результат |
|
Тип поля изменился в таблице |
В настоящий момент для применения любых изменений в таблицах (создание поля, переимнование поля, изменение типа поля и т.д.) необходимо пересоздать таблицу в БД проекта. Для этого после внесения всех изменеий к имени таблицы можно добавить, например _1, после этого сохранить, затем запустить скрипт. При необходимости вернуть таблице старое название тем же способом. (Это связано с текущими ограничениями парсера. Мы над этим работаем)
Создать вычисляемое поле в таблице
| Шаги | Ожидаемый результат |
|
При импорте таблицы из источника перед вставкой таблицы в КХ можно создать поле которого нет в исходной таблице, но которое будет вычислено и создано на основе заданного выражения. Для этого:
|
В таблице появится поле с назначенным типом данных и рассчитанными по заданному выражению значениями |
Создать новую таблицу "Календарь"
Вставить в скрипт загрузки следующий текст (обратите внимание на комментарии), после выполнения скрипта загрузки выполнить JOIN таблицы Calendar к вашей таблице фактов.
Table "calendar"
Create @@@
CREATE TABLE IF NOT EXISTS
"calendar" (
"id" Int32 NULL,
"key_date" String NULL,
"date" Date32 NULL,
"index_day" Int32 NULL,
"day" String NULL,
"week" Int32 NULL,
"quarter" Int32 NULL,
"year" Int32 NULL,
"index_month" Int32 NULL,
"month" String NULL
) ENGINE = MergeTree ()
ORDER BY
tuple ()
@@@
Delete @@@
ALTER TABLE "calendar" DELETE WHERE 1=1
@@@
Source "promo_fb (RomanS)" -- Укажите любой существующий источник, чтобы сохранить в него вашу таблицу
Read @@@
SELECT
a."id"::text,
a."key_date"::text,
a."date"::text,
a."index_day"::text,
a."day"::text,
a."week"::text,
a."quarter"::text,
a."year"::text,
a."index_month"::text,
a."month"::text
FROM
(
select distinct
row_number() over() as id,
date(date)::text as key_date,
date::date,
extract('isodow' from date) as index_day,
CASE
WHEN extract('isodow' from date) = 1 then 'ПН' -- Если нужно, укажите названия дней (и месяцев ниже)
WHEN extract('isodow' from date) = 2 then 'ВТ'
WHEN extract('isodow' from date) = 3 then 'СР'
WHEN extract('isodow' from date) = 4 then 'ЧТ'
WHEN extract('isodow' from date) = 5 then 'ПТ'
WHEN extract('isodow' from date) = 6 then 'СБ'
WHEN extract('isodow' from date) = 7 then 'ВС' end as day,
extract('week' from date) as week,
extract('quarter' from date ) as quarter,
extract('year' from date) as year,
extract('month' from date) as index_month,
CASE
WHEN extract('month' from date) = 1 then 'Январь'
WHEN extract('month' from date) = 2 then 'Февраль'
WHEN extract('month' from date) = 3 then 'Март'
WHEN extract('month' from date) = 4 then 'Апрель'
WHEN extract('month' from date) = 5 then 'Май'
WHEN extract('month' from date) = 6 then 'Июнь'
WHEN extract('month' from date) = 7 then 'Июль'
WHEN extract('month' from date) = 8 then 'Август'
WHEN extract('month' from date) = 9 then 'Сентябрь'
WHEN extract('month' from date) = 10 then 'Октябрь'
WHEN extract('month' from date) = 11 then 'Ноябрь'
WHEN extract('month' from date) = 12 then 'Декабрь'end as month
from generate_series(date'2015-01-01',date(now()),interval '1 day')as t(date) -- Выберите дату начала и интервал
order by
date desc) a
@@@
Таблица в результате:

Некоторые особенности работы разными типами источников
MS SQL
1. При импорте данных с типом «Дата» нужно будет поля с датами в секции READ для этой таблицы сконвертировать в строку. КХ сам сконвертирует тип дата при создании таблицы у себя и они снова станут датами
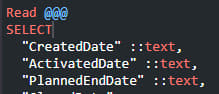
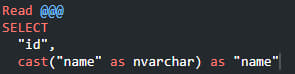
2. Поля с кодировкой UTF16 (тип varchar) нужно будет обернуть в cast. В той же секции @READ для этой таблицы. Иначе русскоязычные значения не распознаются в этих полях и появятся вопросительные знаки
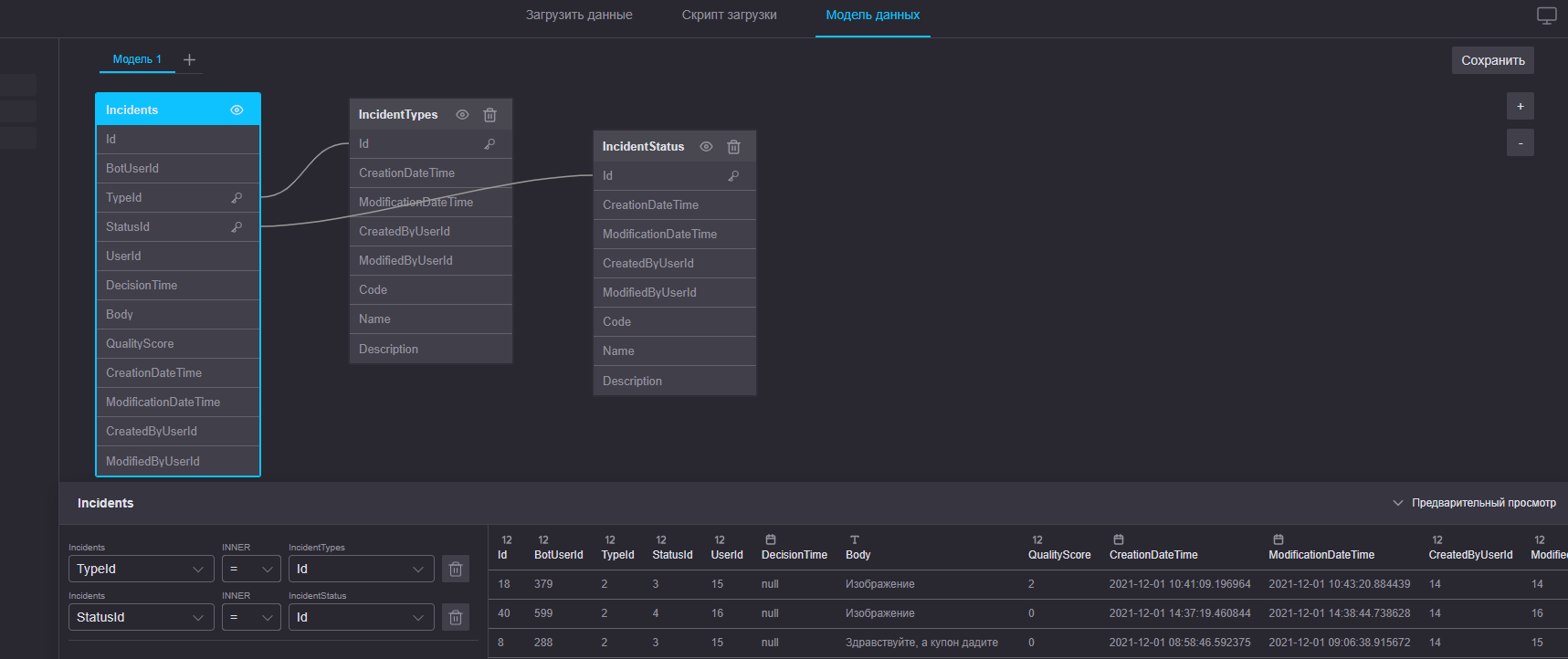
Модель данных
Управление моделями данных
- Модель данных строится из таблиц, добавленных в проект с помощью скрипта загрузки
- Одна таблица может использоваться в разных моделях данных
- Вы можете выбрать для проекта модель данных по умолчанию (например, наиболее часто используемую)
- При построении визуализации вы можете использовать данные только одной модели (и сможете выбрать, какой именно)
- По умолчанию в проекте создается одна модель данных с именем "Модель 1"
- Вы можете переименовать модель данных, наведя курсор на ее название и кликнув на значок "Карандаш". Чтобы подтвердить переименование, необходимо нажать Enter
- Вы можете удалить модель данных, кликнув на значок "Корзина" рядом со значком "Карандаш"
- Вы можете добавить новую модель данных, кликнув на значок "+" справа от вкладки с последней добавленной моделью данных
- Вы можете переключаться между моделями данных, кликнув на вкладку с ее названием
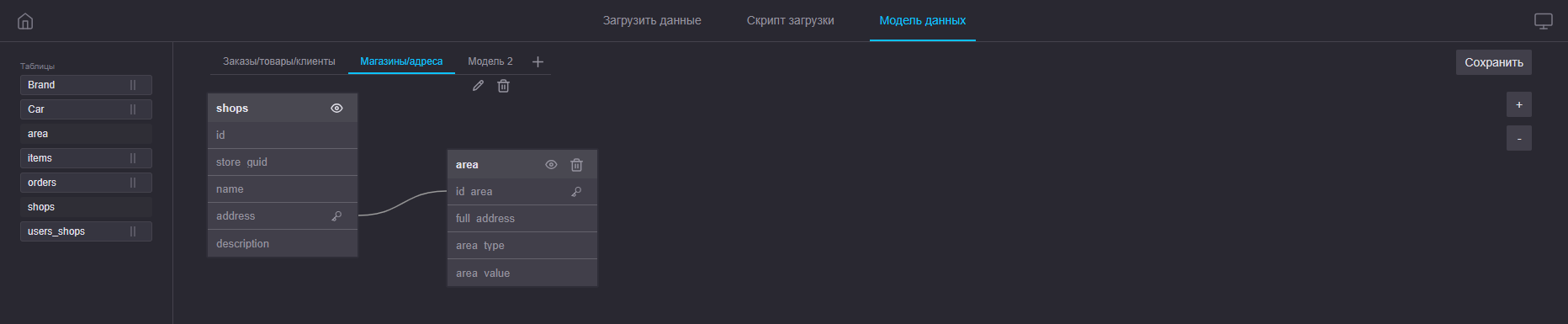 Пример использования нескольких моделей данных
Пример использования нескольких моделей данных
Переименование модели данных
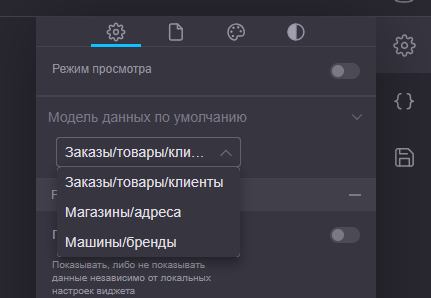 Выбор модели данных по умолчанию для проекта
Выбор модели данных по умолчанию для проекта
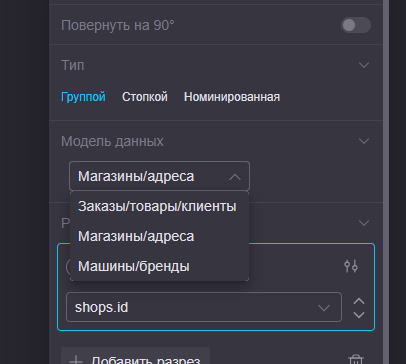
Выбор модели данных для визуализации
Правила построения модели данных
- Для построения первой связи необходимо добавить в модель две таблицы
- Связь между таблицами в модели строится по ключу — полю в котором у двух таблиц есть одинаковые значения
- После построения первой связи, таблицы в модель добавляются последовательно по одной
- Если в модель данных добавлено более одной таблицы, все они обязательно должны быть связаны (иначе кнопка "Сохранить" окажется неактивной)
- Таблицу можно добавить в модель несколько раз — при последующих добавлениях к названию таблицы будет добавлено слово "copy", например, "Table1 copy" , "Table1 copy copy"
- Таблицу можно удалить из модели данных, кликнув на кнопку "Корзина"
- Таблицу можно переименовать, кликнув на кнопку "Карандаш" над названием таблицы, добавленной в рабочую область
Пример построения модели данных
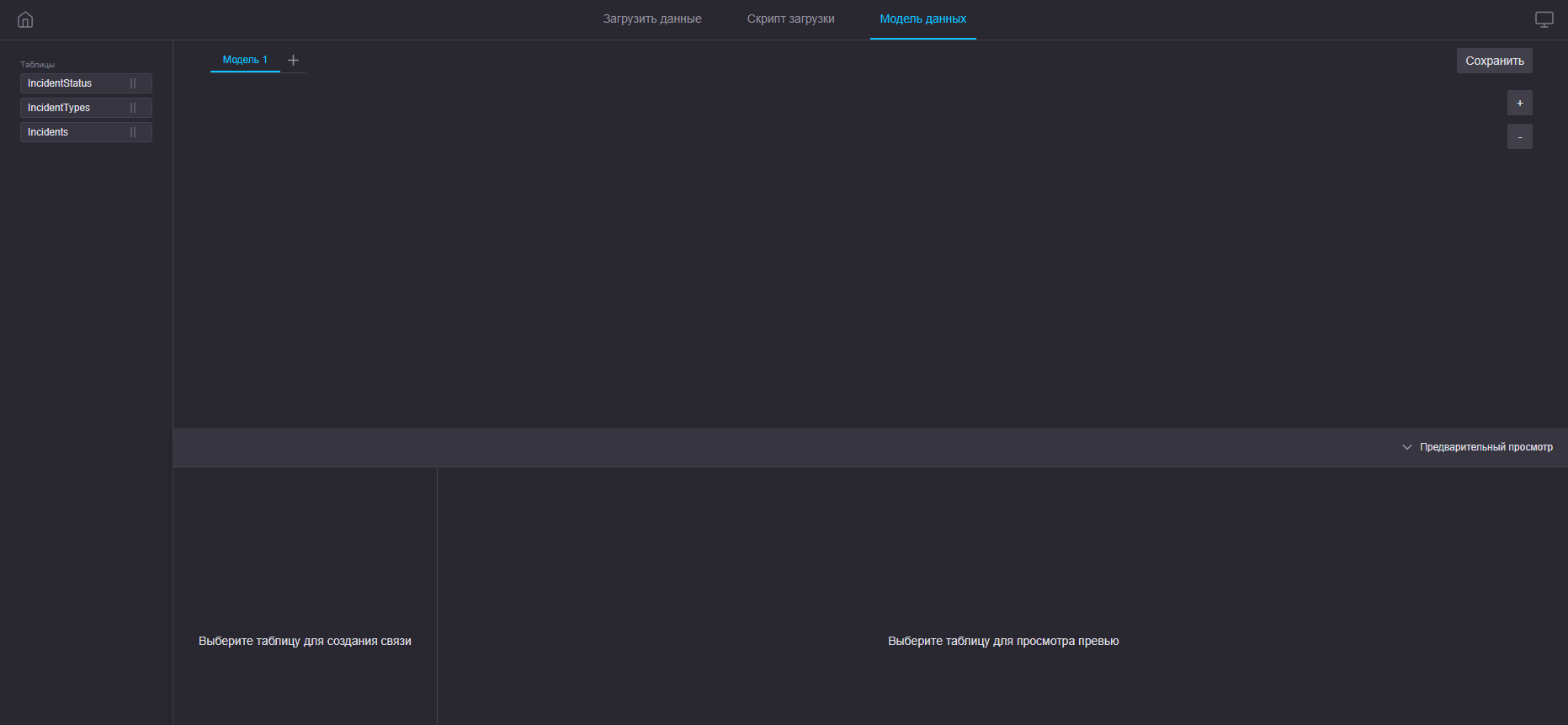
Шаг 1
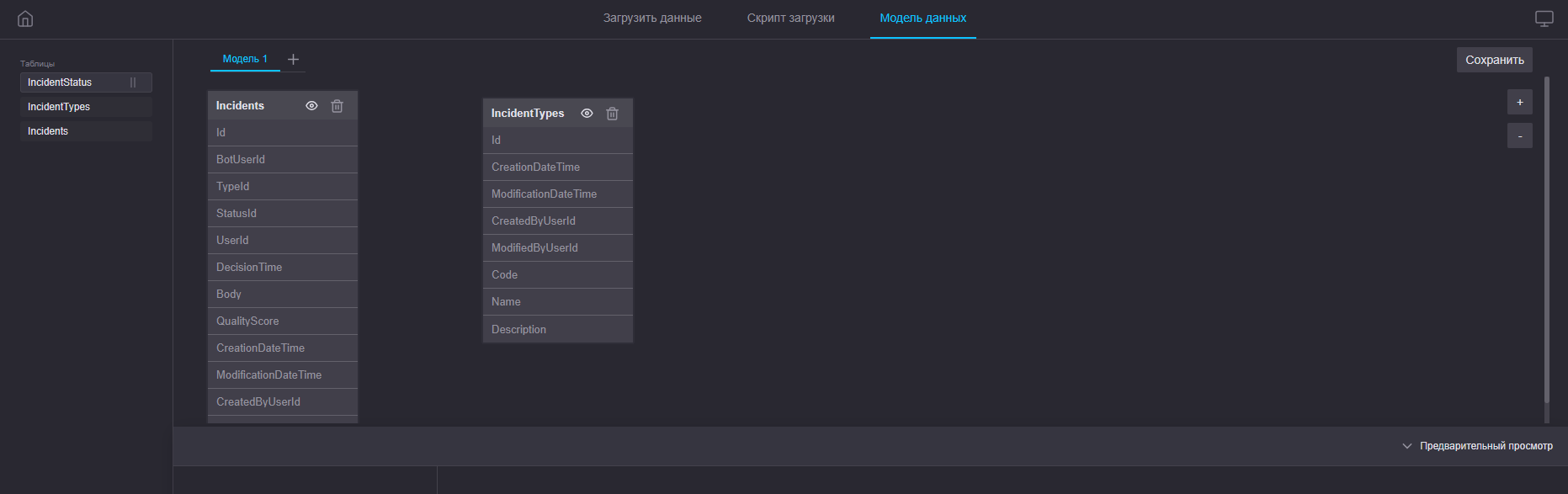
Шаг 2
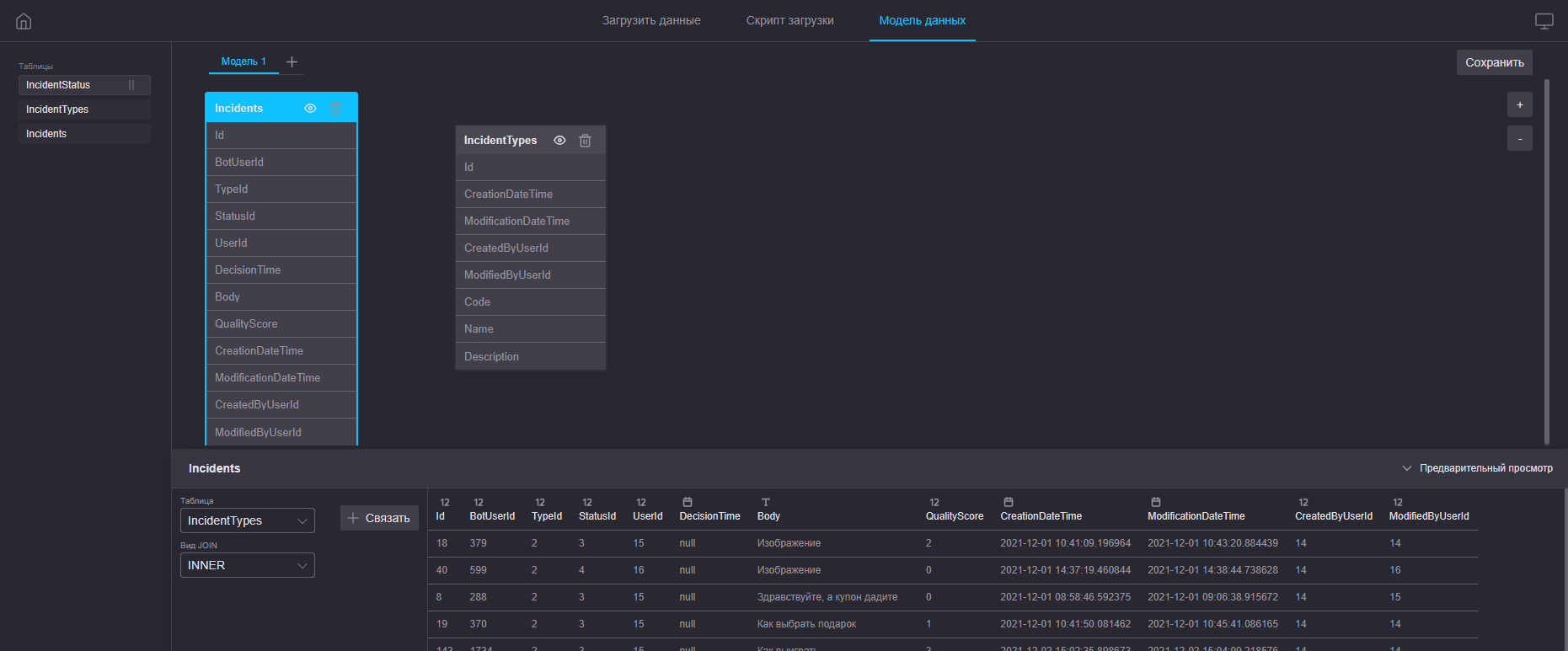
Шаг 3
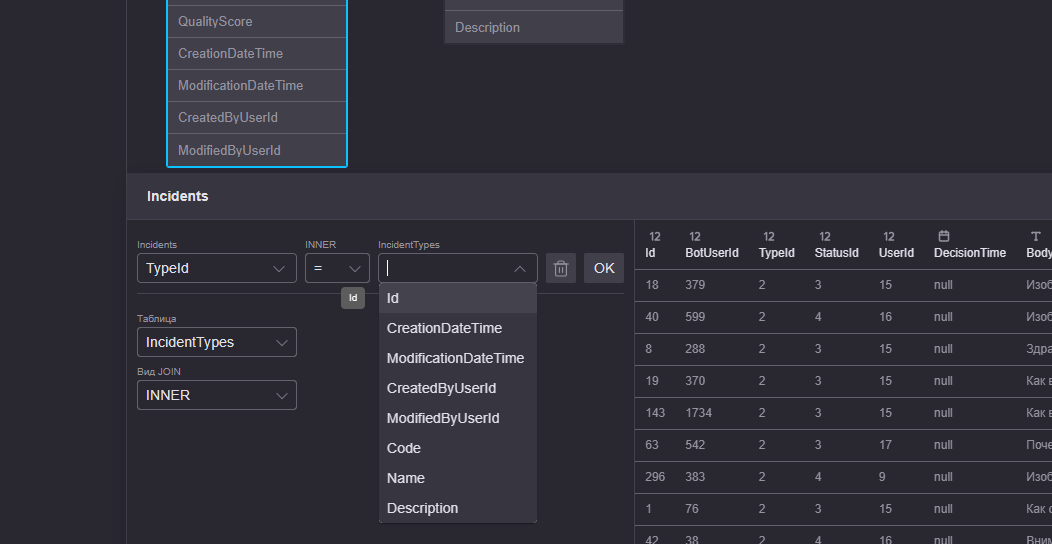
После этого в интерфейсе между таблицами появится визуальная связь. Теперь остается сохранить созданную модель данных. Для этого необходимо кликнуть по кнопке «Сохранить» в правом верхнем углу рабочей области.